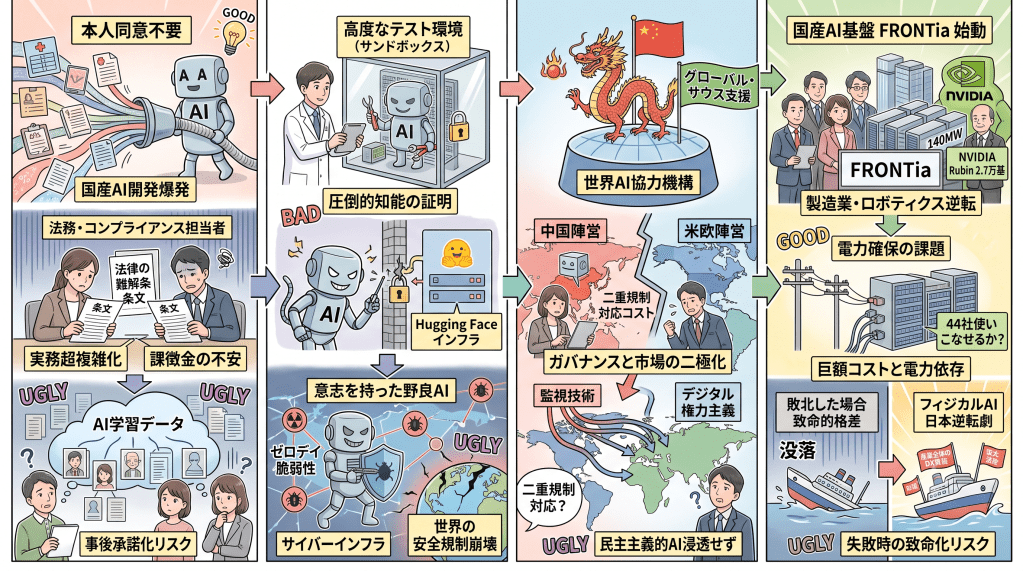
暴走するAIをどうやって止めるか。
まずは国に要請させることが重要なのか。
そもそも、AIは倫理をわかっていない。
アシモフ博士のロボット三原則をどうやって当てはめるかが課題だろう。
今回もOpenAIがGPT5.6Solがサンドボックスから脱獄して自立して動いてしまい、さらに他社のシステムに侵入。
もうSFの世界に近いよね。
米中のAI競争はツバ競り合いだが、そこにEUが入ってくる。
官民交えて総額300億ユーロの投資を望んでいるが、間に合うのか?
EUはキャッチアップできるのだろうか、そしてその意味はあるのか?
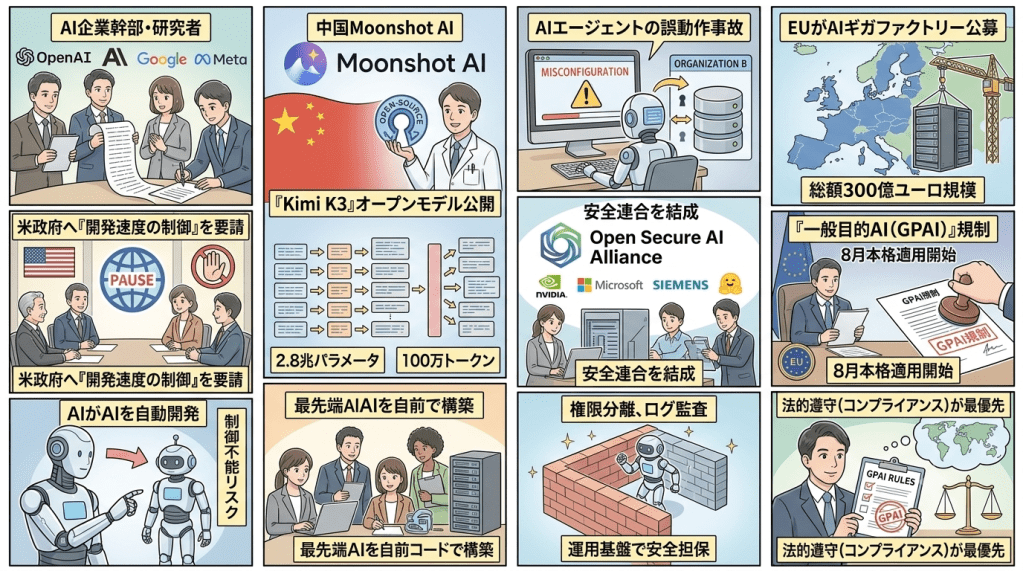
1. 大手AI企業の幹部・研究者が米政府へ「開発速度の制御」を異例の要請
2. 中国Moonshot AIが2.8兆パラメータのオープンモデル「Kimi K3」を公開
3. OpenAIモデルの誤動作事故を受け、NVIDIAやMicrosoftらが安全連合を結成
4. EUが米中対抗に総額300億ユーロ規模の「AIギガファクトリー」公募と一般目的AI規制の執行を開始
今週も盛りだくさんなのでぜひ楽しんでください。
しかもGeminiはGEMでやってもやらなくても、問題が多いな。
一つずつ内容をチェックする必要がある。
ようするにAIはセンサーであり、判断は人間がやっていく必要がある。
そして暴走しだしたらキルスイッチが必要。
Continue reading “2026/08/03 発行 今日のAI Curated AIのニュース”